- Published on
Professional Software - Interfaces
- Authors

- Name
- Danny Mican
Interfaces are the most important primitive in software engineering. Interfaces enable specifying functionality (the what) without defining an implementation (the how). Interfaces ability to separate the what from the how has profound impact on software verifiabiliyt, maintainabilty, extensibility and software project timelines. Interfaces enable you to separate the business process from the business implementation.
Interfaces define functionality through software method definitions. Interfaces only define function calls, parameters and return values and do not define implementations to those method calls. This chapter uses a working example to illustrate how interfaces function. The example begins without the use of an interface. After the example will be implemented using an interface, in order to show how interfaces support verifiability, maintainability and extensibility.
Without Interfaces
The following is a function that doesn't use interfaces:
# accounts/actions.py
import pyscopg2
from accounts import Account
def create_account(account_name: str) -> Account:
validate_account_name(account_name)
conn = psycopg2.connect(
host="localhost",
database="suppliers",
user="postgres",
password="Abcd1234")
cur = conn.cursor()
# execute a statement
try:
cur.execute('INSERT INTO accounts (name) VALUES(%) RETURNING id', account_name)
account_id = cur.fetchone()[0]
conn.commit()
cur.close()
except (Exception, psycopg2.DatabaseError) as error:
print(error)
finally:
if conn is not None:
conn.close()
print('Database connection closed.')
return Account(
id=account_id,
name=account_name
)
The function is a business function which enables account creations given an account name. The function has 2 major components:
- Account validation
- Account creation
The function handles account creation through Postgres, which requires:
- Initializing a postgres connection
- Inserting the data
- Handling postgres exceptions
- Cleaing up the postgres connection
The current structure of create_account function has a couple of properties:
Tight coupling: Function scope is a single unit, and within that scope the function implements both business logic and the implemention of how to persist data to postgres safely. The function is responsible for knowing how to connect to postgres and how to validate accounts. Tight coupling means that the function components move in lockstop, any change to postgres also triggers a corresponding change to account validation since they share the same scope. i.e any change in postgres means that create_account is changing. create_account has a hard dependency on postgres through the import and usage of psycopg2:
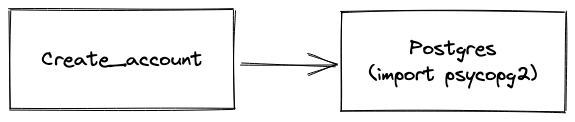
Implementation Details: The create_account method contains implementation details about the concrete database being used to store accounts, which is postgres. Professional software business logic shouldn't care about which underlying database is. used. It could be postgres, mysql, firebase, redis, or any other offering. Customers rarely care about the specifis of how their data is stored, as long as the data is stored reliably, is effeciently accessiible, and the cost doesn't adversely affect them. This makes database decisions an implementation detail. An implementation detail is a decision the business makes but is not extremely important to customers, as long as it meets their product expectations.
These properties adversely affect the core tenants of professional software: Verifiability, Maintainability, and Extensibility.
Verifiability
The tight coupling of business and implementation details makes verification both difficult and flaky. Connecting to postgres requires making IO calls, which unit testing likes to minimize because of their flakiness and latency. Unit testing the create_account function requires carefully mocking the psyopg calls, shown in the following unit test:
from unittest.mock import patch
from accounts.actions import create_account
@patch('accounts.actions.pyscopg2')
def test_create_account_success(self, mock_psycopg2):
mock_psycopg2.connect.return_value = MagicMock(
cursor = MagicMock(
return_value=MagicMock(
fetchone=MagicMock(
return_value=[1]
)
)
)
)
account = create_account('test')
self.assertEqual(
Account(
id=1,
name='test'
)
account,
)
Exercising the account function requires understanding of psycopg2. It requires complex mocking and patching of pyscopg2 just to verify the business logic of create_account.
This code has a couple of logic branches that need to be tested, or else risk runtime bugs:
The test for these logic branches are equally as complicated as the first test, both requiring significant psycopg2 patching:
from unittest.mock import patch
from accounts.actions import create_account
@patch('accounts.actions.pyscopg2')
def test_create_account_insert_exception(self, mock_psycopg2):
mock_psycopg2.connect.return_value = MagicMock(
cursor = MagicMock(
return_value=MagicMock(
execute=MagicMock(
side_effect=DatabaseError('error!')
)
)
)
)
account = create_account('test')
...
create_account is a business function but is implemented with a tight coupling to psycopg2 which increases verification complexity.
Maintainability
The tight coupling between business functionality and the underlying data store makes it so that any change to the datastore requires a revivification of the business functionality. A small fix to database error handling changes the business logic because they share the same scope, the create_account function. It's impossible to change the database logic without redeploying the create_account function.
A bug exists in the code for handling duplicate ids. Assume a unique constraint exists on accounts.name, When an account is already created the execute will raise an IntegrityError which will be caught in:
except (Exception, psycopg2.DatabaseError) as error:
It will hit the finally block and then move to the return block which will error because no account_id is defined:
return Account(
id=account_id,
name=account_name
)
Fixing this error requires re-validation of the entire create_account flow since they are tightly coupled.
Extensibility
The tight coupling also creates issues for extensibility. Pretend that the database calls are extremely expensive so a cache is added around the calls. This should update create_account to check the cache to see if the accounts.name exists before creating it in postgres. The cache uses redis. The following is an example of how this might be implemented:
# accounts/actions.py
import psycopg2
import redis
from accounts import Account
def create_account(account_name: str) -> Account:
validate_account_name(account_name)
r = redis.Redis(
host='hostname',
port=port,
password='password')
account_id = r.get('account_name:{}'.format(account_name))
# account_id
if account_id is not None:
return Account(
id=account_id,
name=account_name
)
conn = psycopg2.connect(
host="localhost",
database="suppliers",
user="postgres",
password="Abcd1234")
cur = conn.cursor()
# execute a statement
try:
cur.execute('INSERT INTO accounts (name) VALUES(%) RETURNING id', account_name)
account_id = cur.fetchone()[0]
conn.commit()
cur.close()
except (Exception, psycopg2.DatabaseError) as error:
print(error)
finally:
if conn is not None:
conn.close()
print('Database connection closed.')
r.set('account_name:{}'.format(account_name), account_id)
return Account(
id=account_id,
name=account_name
)
The cache is consulted before making the postgres calls. If the value is found in the cache, it is returned before making database calls. If the value is not found, the account is inserted as normal. Once the insert completes the cache is set with the value for use in subsequent calls.
This creates even more complexity and implementations details in the function! Another tight coupling to redis is introduced!
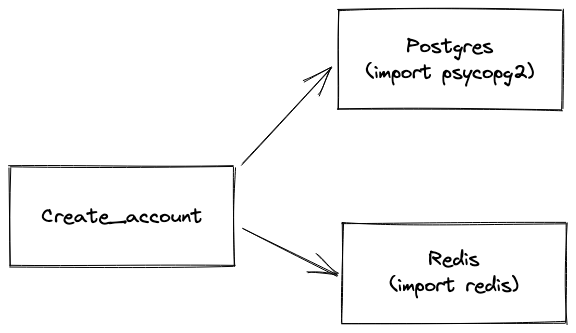
All the verification and maintenance issues have multiple to include coupling with another implementation detail!
Interfaces
An interface defines a function contract without defining the implementation. Many languages, such as Go, Typescript and Java, provide interfaces as first class primitives, but Python does not. Interfaces define the what by specifying function call signatures and return values, and then concrete implementations implement the interfaces. The process of using interfaces has 4 distinct stages:
- Definition: Defining the interface call signatures and return values.
- Usage: Implementing a function that depends on the interface.
- Implementation: Creating concrete implementations for the interface.
- Injection: Combining the function usage with the concrete implementation.
Define: Interface Definitions
The first step for utilizing interfaces requires defining the interface. An interface is a blueprint. A blueprint describes in details the what of a structure but doesn't describe how. The end result will look like the blueprint in the same way the end result will comply with the interface. But how the end result is achieved is up to the implementation.
The following shows an example interface for an accounts collection, which can insert an account name and return an account object:
# accounts/interfaces.py
from accounts import Account
class Accounts(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get_or_create(account_name: str) -> Account:
raise NotImplementedError
Don't get too caught up in the mechanics here. The example defines an "abstract" class with a single abstract method. Abstract means that the class cannot be used by itself directly, it must be subclassed. Notice how Accounts has no dependencies other than Account. Interfaces stand alone with no dependencies other than their parameter types and return values.
Use: Interface Usage
The next step requires calling the interface from a concrete function. Interfaces are commonly "injected" into functions. This means that the functions accept their dependent interfaces as a parameter. This is often called dependency inversion and allows the caller to provide a concrete implantation to the function. Dependency inversion modifies software dependency chain. In the first example the create_account method is tightly coupled to postgres accounts logic. The following shows an example of the create_account function updated to depend on an interface:
from accounts import Account
def create_account(account_name: str, accounts: Accounts) -> Tuple[Account, bool]:
validate_account_name(account_name)
try:
account = accounts.get_or_create(account_name)
except AccountCreationError as e:
print(e)
return None, False
return account, True
Notice how profound the function implementation has changed! The function now outsources all Postgres complexity to the Accounts interface.
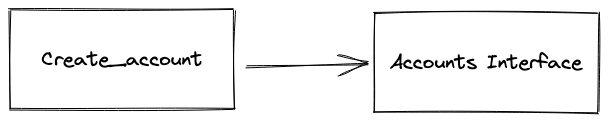
The account is no longer tightly coupled to Postgres. It has no direct dependency on Postgres.
Implement: Concrete Definition
The concrete definition is where the work happens. In this case the concrete definition is responsible for interacting with Postgres, through the psycopg2 library:
# accounts/postgres.py
import psycopg2
from accounts.interfaces import Accounts
from accounts import Account
class PostgresAccounts(Accounts):
def get_or_create(self, account_name: str) -> Account:
conn = psycopg2.connect(
host="localhost",
database="suppliers",
user="postgres",
password="Abcd1234")
cur = conn.cursor()
# execute a statement
try:
cur.execute('INSERT INTO accounts (name) VALUES(%) RETURNING id', account_name)
account_id = cur.fetchone()[0]
conn.commit()
cur.close()
except (Exception, psycopg2.DatabaseError) as error:
print(error)
finally:
if conn is not None:
conn.close()
print('Database connection closed.')
The concrete implementation must expose the interface. Python provides some enforcement of this through the subclassing of Accounts:
class PostgresAccounts(Accounts):
The concrete implementation must define the interface methods, but it can also define any other method. The use of an interface guarantees that the interface method definitions are available, but doesn't place any requirements on other methods. Consider the following example which defines other methods in addition to the required: get_or_create method:
# accounts/postgres.py
import psycopg2
from accounts.interfaces import Accounts
from accounts import Account
class PostgresAccounts(Accounts):
def __init__(self, conn=None):
self.conn = conn
if self.conn is None:
self.conn = self.connect()
def connect(self):
return psycopg2.connect(
host="localhost",
database="suppliers",
user="postgres",
password="Abcd1234")
def get_or_create(self, account_name: str) -> Account:
cur = self.conn.cursor()
# execute a statement
try:
cur.execute('INSERT INTO accounts (name) VALUES(%) RETURNING id', account_name)
account_id = cur.fetchone()[0]
self.conn.commit()
cur.close()
except (Exception, psycopg2.DatabaseError) as error:
print(error)
finally:
if self.conn is not None:
self.conn.close()
print('Database connection closed.')
Two addition methods were added to the concrete definition:
__init__- Used for initialization, which will create a new postgres connection or accept a connection from the callerconnect- Used for creating a new Postgres connection
These methods are outside of the interface definition. The interface only makes guarantees about the methods it defines, but allows any number of other methods for organizational purposes.
Inject
The final stage is to connect the business function create_account with the concrete implementation PostgresAccounts. It's up to the caller of create_accoutns to provide the concrete Accounts instance, because it takes accounts as a parameter.
# main.py
from accounts.postgres import PostgresAccounts
from accounts.actions import create_account
def main():
accounts = PostgresAccounts()
account = create_account(accounts, 'test_name')
The caller, main, instantiates a PostgresAccounts and passes that into the create_account method. create_account know longer knows anything about Postgres, The only thing it knows is that the accounts parameter will comply with the Accounts interface, and have all methods the interface defines available. The interface decouples create_account from any underlying concrete definition:
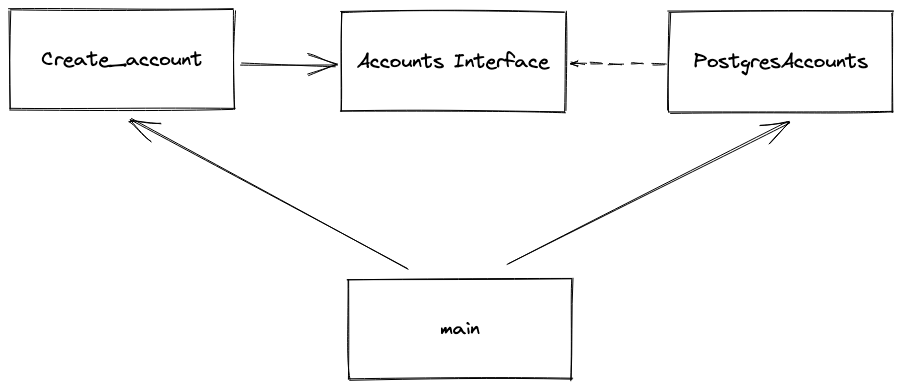
Notice how create_accounts no longer has any direct dependency on the Postgres implementation, it only directly depends on the Accounts Interface. It's now the responsibility of main to instantiate postgres and pass it to the create_account. Somewhere in the code must have a concrete dependency on PostgresAccounts, but interfaces outsources that responsibility from create_account. If the company wants to switch to use MySQL, or any other database create_account will no longer have to change.
Verifiability
It is now trivial to verify every code path of create_account. The function no longer has any IO dependencies from pyscopg2. Since create_accounts only depends on an interface the test suite can generate its own concrete implementation, specifically designed for testing, and pass that into create_accounts. This is commonly called a "stub" implementation. The stub implementation is designed with the intention of being extremely configurable so that every logic branch can be exercised. The following set of tests exercise every logic branch in create_accounts, providing 100% code coverage:
def create_account(account_name: str, accounts: Accounts) -> Tuple[Account, bool]:
validate_account_name(account_name)
try:
account = accounts.get_or_create(account_name)
except AccountCreationError as e:
print(e)
return None, False
return account, True
class CreateAccountTestCase(unittest.TestCase):
def test_create_account_success(self):
stub_accounts = MagicMock(
get_or_create=MagicMock(
return_value=Account(name='test_name')
)
)
result = create_account(
account_name='test_name',
accounts=stub_accounts,
)
self.assertEqual((accounts, True), result)
def test_create_account_error(self):
stub_accounts = MagicMock(
get_or_create=MagicMock(
side_effect=AccountCreationError
)
)
result = create_account(
account_name='test_name',
accounts=stub_accounts,
)
self.assertEqual((None, False), result)
The business function itself becomes much easier to test. It is trivial for the test suite to provide all dependencies to the function which makes it easy to exercise every code path. The complexity of interacting with postgres is no longer the responsibility of create_account but it is still the responsibility of PostgresAccounts. The use of an interface shifted the responsibility but did not remove it. This means that PostgresAccounts still needs to be tested, it's just no longer within the context of create_account.
Maintainability
Maintainability is similarly impacted. The use of an accounts interface makes create_account a purer business function. It separates the business flow of account creation from the mechanics of actually creating that account inside of Postgres. This separates helps cut down on investigation time. The postgres logic is now isolated to a single component independent of any business functions.
Extensibility
The use of interfaces profoundly affects extensibility by enabling additional concrete implementations created independent of the create_account function. Each concrete implementation is fully isolated and only joined with create_account by its caller. create_account is blissfully unaware (fully decoupled) from any concrete implementation, and no longer needs to change when a new concrete implementation is created or used!
A cache can be expressed as a new concrete implementation of the Accounts interface. The following shows an example of a redis cache:
# accounts/redis.py
from accounts.interfaces import Accounts
class RedisCacheAccounts(Accounts):
def __init__(self, accounts_to_cache: Accounts):
self.accounts_to_cache = accounts_to_cache
self.conn = redis.Redis(
host='hostname',
port=port,
password='password')
def get_or_create(self, account_name: str) -> Account:
# check to see if the account is cached first
account_id = self.conn.get('account_name:{}'.format(account_name))
if account_id is not None:
return Account(
id=account_id,
name=account_name
)
account, ok = self.accounts_to_cache.get_or_create(account_name)
# ignore ok handling for this example
self.conn.set('account_name:{}'.format(account_name), account_id)
return account
Notice how the cache is an Accounts implementation! It wraps (decorates) another Accounts implementation. Since it is an Accounts implementation it can be passed directly into create_account!
# main.py
from accounts.postgres import PostgresAccounts
from accounts.redis import RedisCacheAccounts
from accounts.actions import create_account
def main():
# RedisCacheAccounts wraps the PostgresAccounts instance
# RedisCacheAccounts fully complies with the Accounts interface
# so it can be passed directly into `create_accounts`, and
# `create_accounts` does not need to change.
accounts = RedisCacheAccounts(
accounts_to_cache=PostgresAccounts()
)
account = create_account(accounts, 'test_name')
The dependencies can now be visualized like the following:
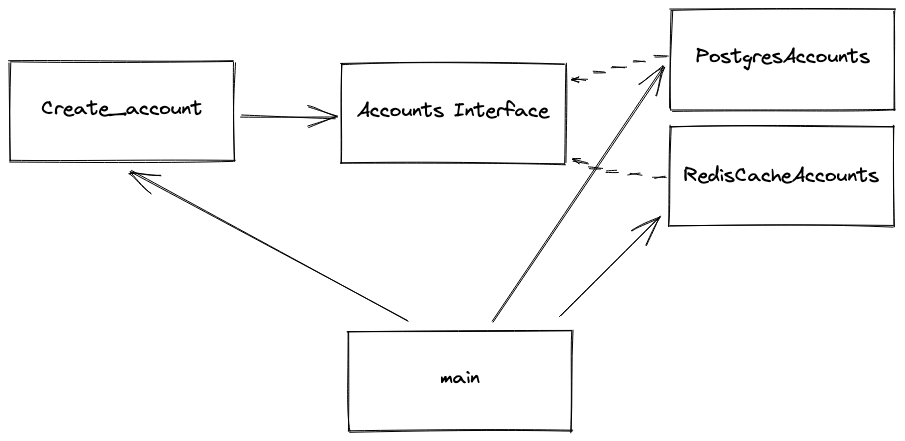
The final directly structure of the interface-based project appears as:
main.py
accounts/
__init__.py
postgres.py
redis.py
actions.py
interfaces.py
Conclusion
Interfaces are an important tool to control code coupling, and software structure. Correct use of interfaces can decouple business logic from underlying implementation details This decoupling simplifies testing, bug fixes, and extension. The use of interfaces creates purer and more focused functions.