- Published on
Deriving Data Lineage From SQL Statements
- Authors

- Name
- Danny Mican
Large data deployments often contain multiple levels of derived tables. Understanding lineage is critical for resolving data downtime and bugs. Often table hierarchies grow out of control with time, which makes maintaining documentation and debugging data issues time intensive and costly. This post describes a method for deriving data lineage from inspecting SQL statements. The database provides a centralized location where many different teams and ETL jobs come together, which makes it a great candidate for generating metadata like Lineage.
Lineage
Database deployments often combine tables to create new tables. Lineage describes how a table is derived, i.e. which tables it depends on. Automated lineage detection is a key offering of many modern data platforms. Automatic detection is extremely important for legacy data warehouses where documentation may be lacking and the cost of documentation is prohibitively expensive.
Lineage provides answers to questions like:
- Which tables does orders depend on?
- Which tables depend on table ___ ?
To illustrate the concept of data lineage, consider a company with 3 different sales channels:
- Enterprise
- SAAS
- Partner
The company houses orders from each of these sales channels in its own table. The company needs a uniform view across all the channels so it ETLs each channel order table into a singular "orders" table, which provides a consistent view of all orders across all channels:
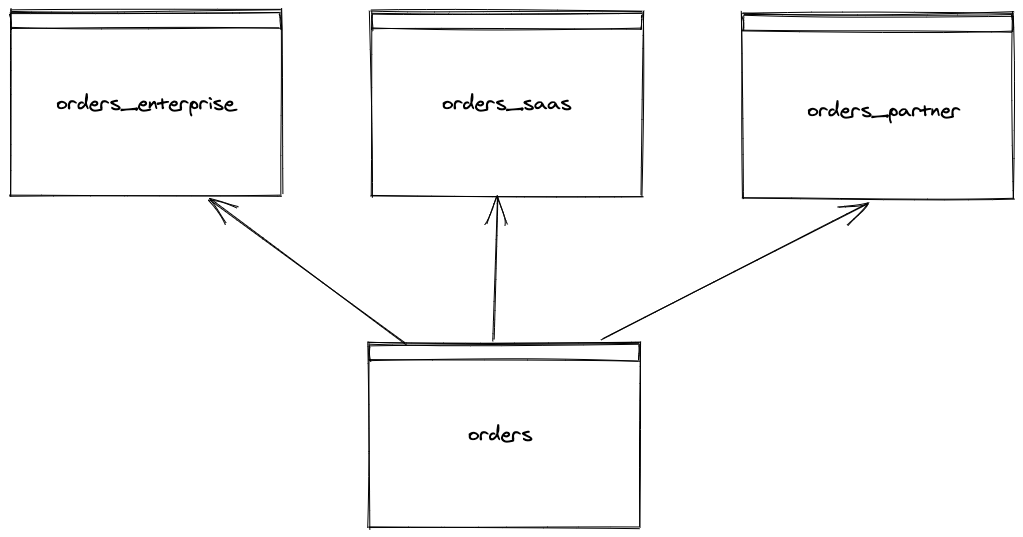
In this case, the lineage of orders is:
- orders_enterprise
- orders_saas
- orders_partner
Lineage becomes really important in understanding the sources of data during pipeline issues. When a stakeholder questions data or data is inaccurate, lineage is often one of the first things consulted, after pipeline execution errors.
Databases can contain 100's to 1000's of tables. This creates extremely complicated lineage graphs. Large deployments have a number of issues which make it difficult to maintain data lineage:
- Documentation is out of date (or may not exist)
- ETL jobs may live in different repos and may be owned by different teams
These issues make an automated solution essential to keeping lineage knowledge up to date.
Deriving Lineage From SQL Statements
The database provides a centralized location where all ETL jobs intersect to create (hopefully) usable data offerings. All database interactions are expressed in terms of SQL statements, and within those statements exist relationships between tables.
Lineage at its core is a graph, meaning there are nodes and edges. The nodes are database tables and the edges are relationships. In databases, relationships between tables are explicitly encoded within SQL statements.
SQL supports a limited number of ways to transfer data between tables. One of the most common is the INSERT INTO... statement.
Assume the orders table is populated by UNIONing each channel specific order table:
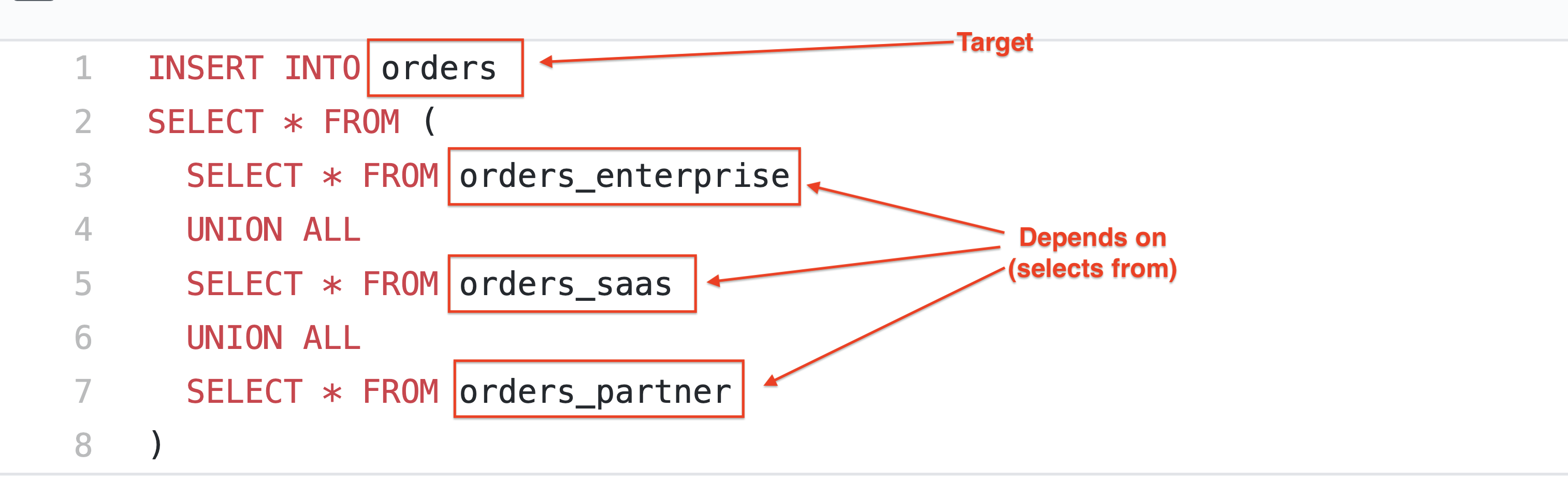
This means lineage can be derived, Given an INSERT INTO SQL statement
lineage(insert_into_sql) = (target, [dependency1, ..., dependencyn])
lineage(orders_insert_into_sql) = (orders, [orders_enterprise, orders_saas, orders_partner])
A full lineage graph can be constructed by analyzing all INSERT INTO statements. Pretend that orders_enterprise is populated from 2 underlying tables:
- salesforce_contracts
- sales_invoices
And the SQL looks like:

Analyzing individual DML insert queries enables building an entire data lineage graph! The lineage of the prior 2 INSERT INTO queries is combined to provide a full view into the "orders" lineage:
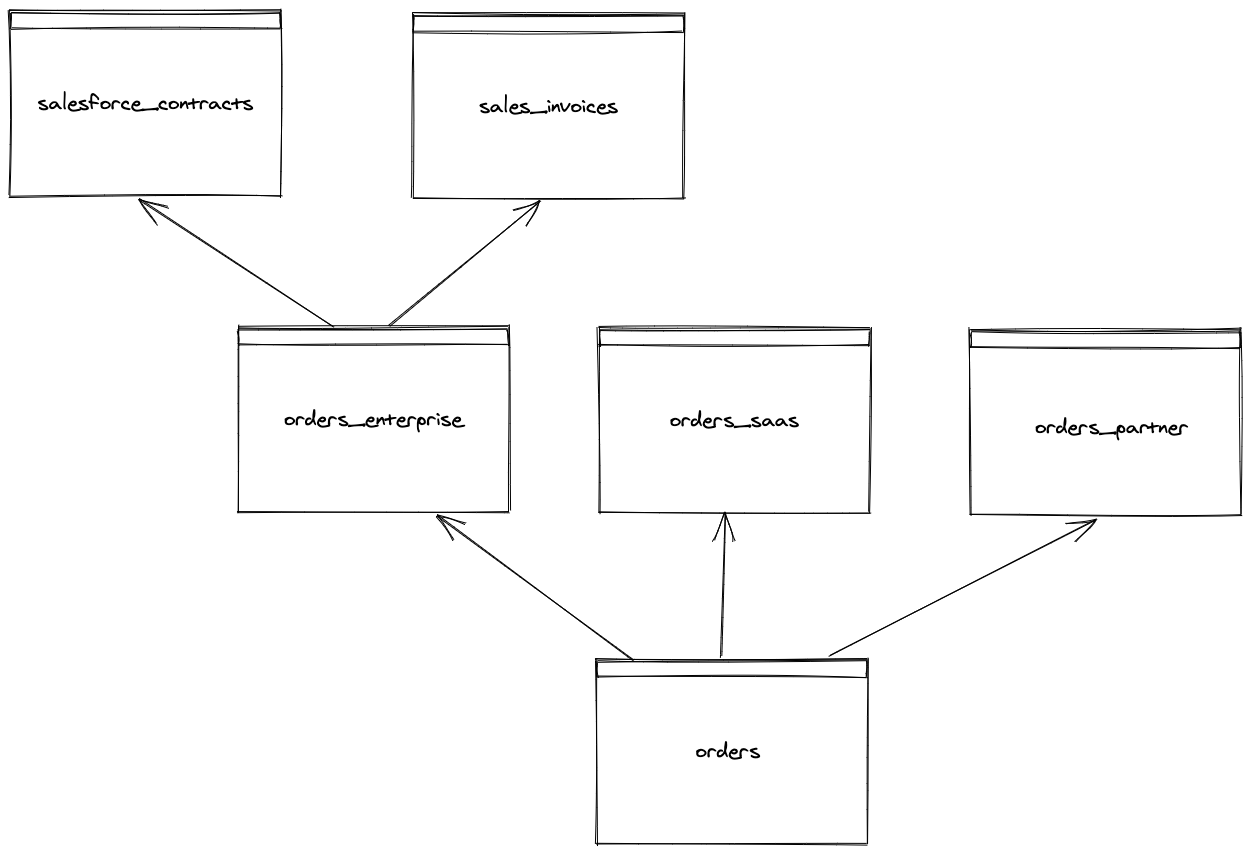
The entire lineage graph can be derived by applying this strategy to every INSERT statement!
Conclusion
Understanding lineage is an important part of data platform operations. Lineage is a primary feature in modern data tools (such as dbt) and data quality providers. Lineage can be automatically derived by inspecting database queries, removing the need to keep pipeline documentation up to date. I'm excited to see the next evolution in affordable data quality tools!