- Published on
Data Operational Maturity
- Authors

- Name
- Danny Mican
Data operations is the act of keeping data pipeline operational, and the data flowing. Data operational maturity focuses on answering:
- Is a pipeline running?
- Is data fresh and consistent?
- Is the data correct?
This data operational maturity model draws heavily from Site Reliability Engineering (SRE). This data operational maturity model treats data operations as a software problem, in the same way that SRE is built on treating operations as a software problem, building observability into the very foundation of data systems.
Maturity Model
Maturity is important to establish uniform approaches and thinking model. What do you think of when asked: “What’s the most foundational part of data operations?”. A maturity model provides an approach to support discussions of tradeoffs and benefits.
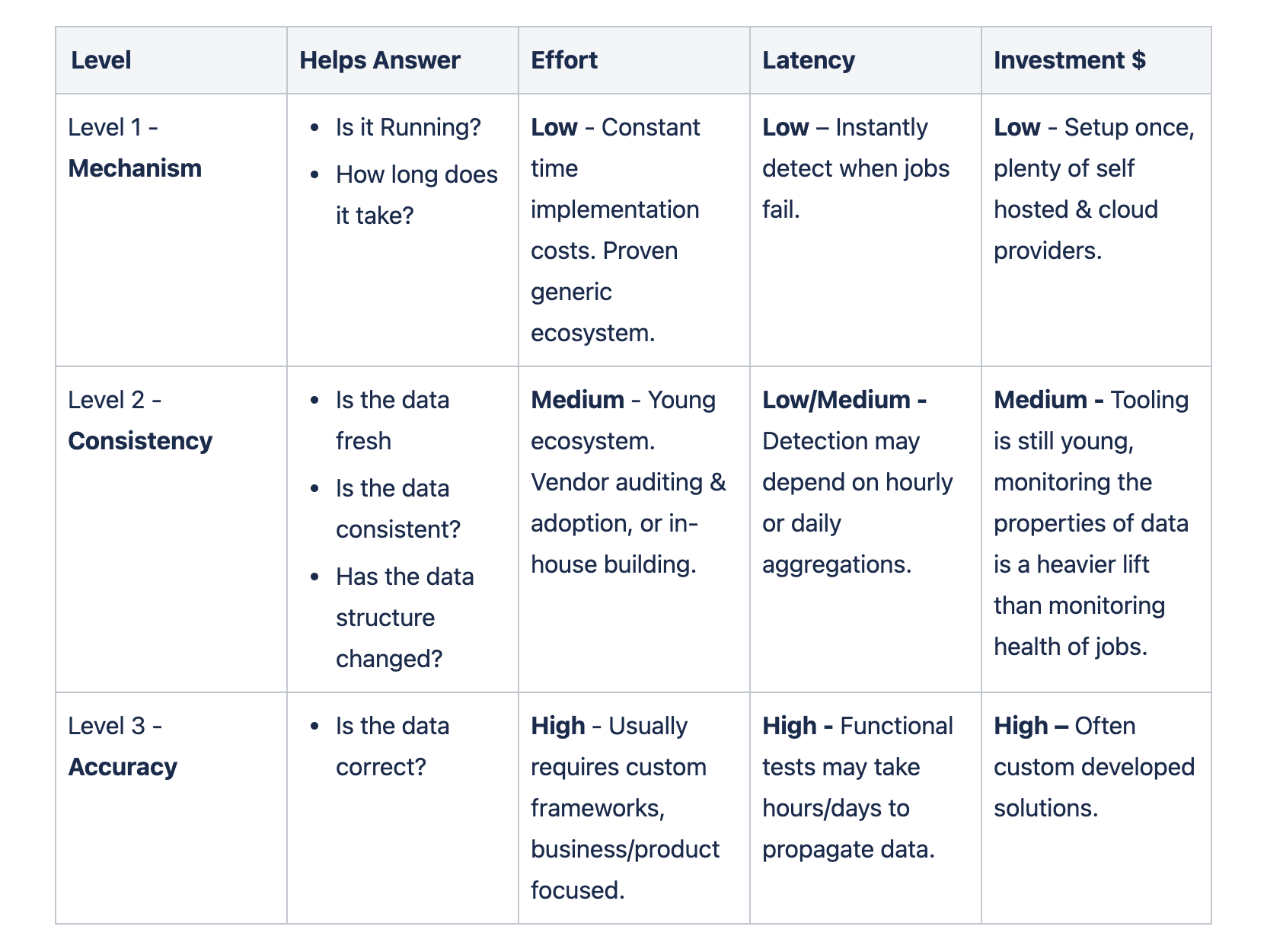
I like to think of data operational maturity composed of 3 distinct levels. Each level has tradeoffs in terms of effort of implementation, fidelity of the signals it provides, and latency of the insights that it surfaces.
Level 1 - Mechanism
Level 1 is the foundational level, which focuses on the health of the data “pipes” and the act of alerting, and responding. Insights at this level are instantaneous. An alert around a job failing can go out immediately after the job fails, and arrive in seconds. When an entity reaches Level 1 maturity it can reliably answer:
- How often are jobs executing?
- Are jobs completing successfully?
- How long do jobs take?
- Are jobs queueing?
- How are underlying resources (such as CPU, memory, and/or disk) utilized?
These metrics are so fundamental Google has an explicit name for them: The Four Golden Signals. These metrics are the cornerstone of data observability maturity in the same way that they are the cornerstone of Site Reliability Engineering at Google.
Investment and effort at this level is relatively low. Many open source and cloud solutions exist to capture these metrics (Datadog, Prometheus, etc). Instrumenting code and pipelines at this level is generally a fixed (constant time) cost. For example, many projects, such as Airflow (a popular workflow engine, think cron for connected jobs), emit metrics natively. Every job it executes surfaces metrics about that execution. Even custom frameworks or libraries only need to be instrumented a single time.
At this level an entity can:
- Detect when failures occur, or execution SLOs, have been breached
- Alert on issues
- Respond to issues
- Use signals gathered at this level to triage issues
Level 2 - Consistency
The next level focuses on the properties of data flowing through the data pipes. A level 2 maturity must answer: “Are the pipes healthy” before focusing on the data flowing across them. If an organization can’t answer if the pipes are healthy and skip to level 2, it’s very difficult to untangle issues with the properties of the data from issues with job health and executions.
Level 2 low to medium latency on insights. Some data properties, such as a drop in stream message rate, or an increase in NULL values, can be detected immediately. Other issues, such as daily volume trends, can only be detected at the aggregation interval (per day in this case). A Level 2 entity can reliably answer questions around the data, such as:
- How much data is flowing through the pipelines?
- How many rows per day per table?
- Does daily table row volume follow historical trends?
- How recent is materialized data (freshness)?
- What are the dependencies for a given piece of data (such as a table)?
Data observability is a market focused on Level 2 data operational maturity, and testament to the effectiveness of this level of maturity, especially for legacy or enterprise data deployments. Monte Carlo is one vendor in this space. At this level an entity can:
- Alert on properties of the data flowing through the pipelines
Level 3 – Accuracy
Level 3 is the final level of maturity and focuses on verifying a data pipeline functions as a whole and can be used to orchestrate value from event creation to end user interaction. Level 3 is implemented as end to end or system test, and focus on system accuracy. Level 3 can also be implemented at the component level in terms of targeted tests that ensure correctness of transformations.
Level 3 can have high latency, because events need to propagate through the entire data pipeline. Accuracy has a very high cost of development and maintenance. A poorly designed solution can provide negative ROI and end up costing the company large amounts of time tending to flaky tests. A Level 3 entity can reliably answer:
- Are key metrics calculated correctly?
- Are core system properties, like privacy, respected?
- Does GDPR (or equivalent) export / forget work?
A level 3 entity can verify the calculation of metrics (such as Daily Active Users) against a specification and ensure that changes to the data systems do not violate the specification. At this level an entity can:
- Alert on accuracy of data solutions
Conclusion
Data operational maturity has a lot of overlap with traditional testing pyramids and site reliability engineering. Quality is a practice and not a single tool. Tools are important to layer in signals but the foundation of Data Operational maturity is detecting, alerting, triaging and remediating issues.