- Published on
Draining the Data Lake (part 1 of 3) - Problems
- Authors

- Name
- Danny Mican
Extract Load Transform (ELT) is the core primitive of the modern data stack. ELT has only been made possible recently due to the availability of cheap object storage, like Amazon's S3. Unfortunately, ELT is a fundamentally sub-optimal primitive for the majority of data use cases making the creation of positive data outcomes an uphill battle for many data organizations.
I believe the answer is to treat data as a software problem in the same way that Google treats operations as a software problem, provisioning data systems instead of solving requests on behalf of individual stakeholders, ushering in an era of software-based data analytics instead of fundamentally human consulting based data offerings. Data needs to be a software problem instead of a human consulting problem.
We can look at software engineering for ways to generate high fidelity business insights, bypassing layers and layers of batch based data engineering modeling and aligning insight ownership with the producing teams. The industry truly needs to modernize with a focus on engineering and removing human data consultants from the loop to succeed and scale. Sustainable business insights don’t happen relying on other teams, they happen when data producers are empowered to be data consumers are empowered to create their own data to query their data generate insights and make data-driven product decisions independent of other teams. Extract-Load-Transform and the Data Lake
Extract-Load-Transform and the Data Lake
ELT is the process of copying raw operational data to a centralized data lake. This is the foundation of the modern data stack. The ELT promotes storing a byte for byte 1 to 1 copy of operational and cloud based data sources to a common shared location, often implemented on AWS S3 (or other object store) called a Data Lake.
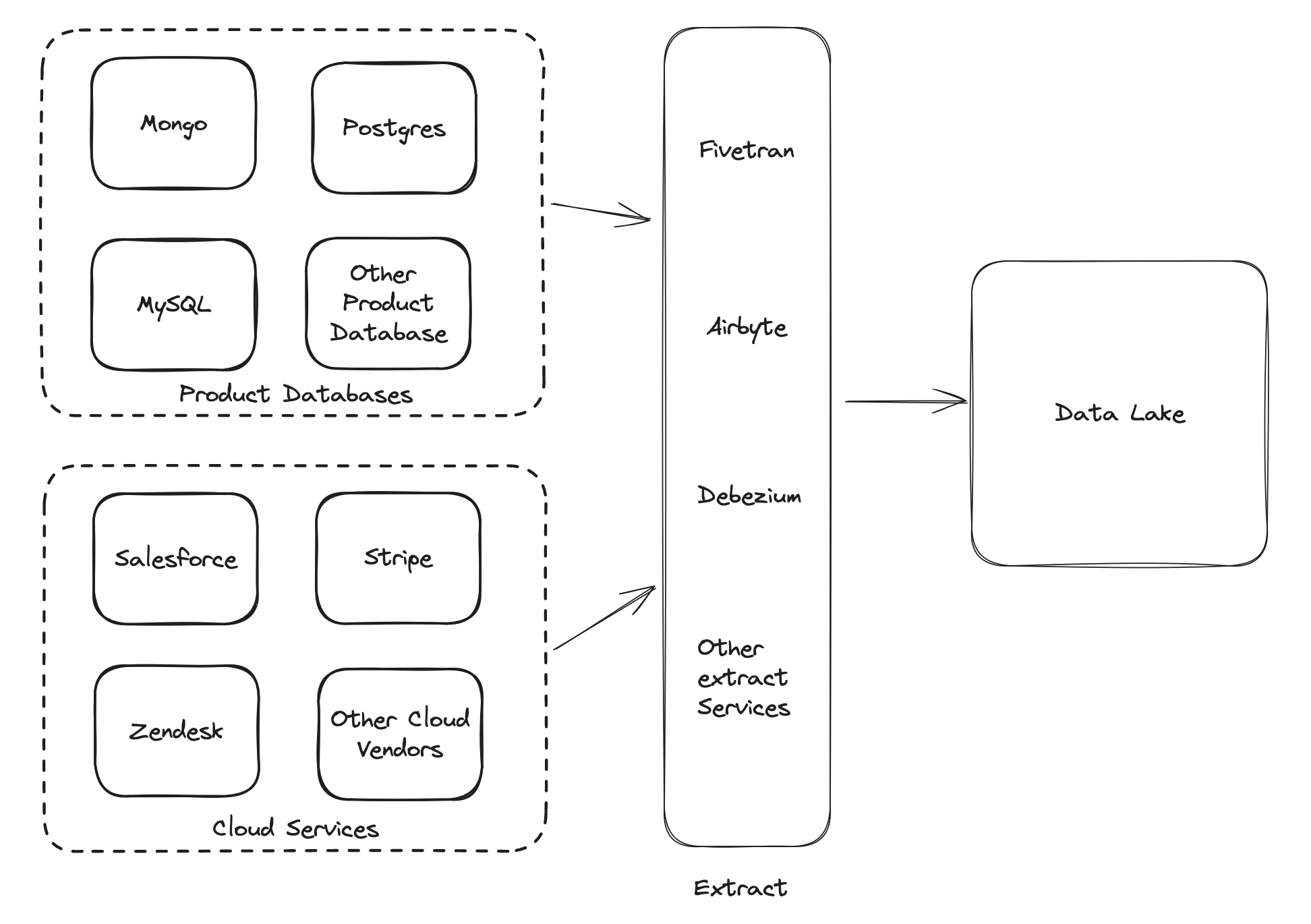
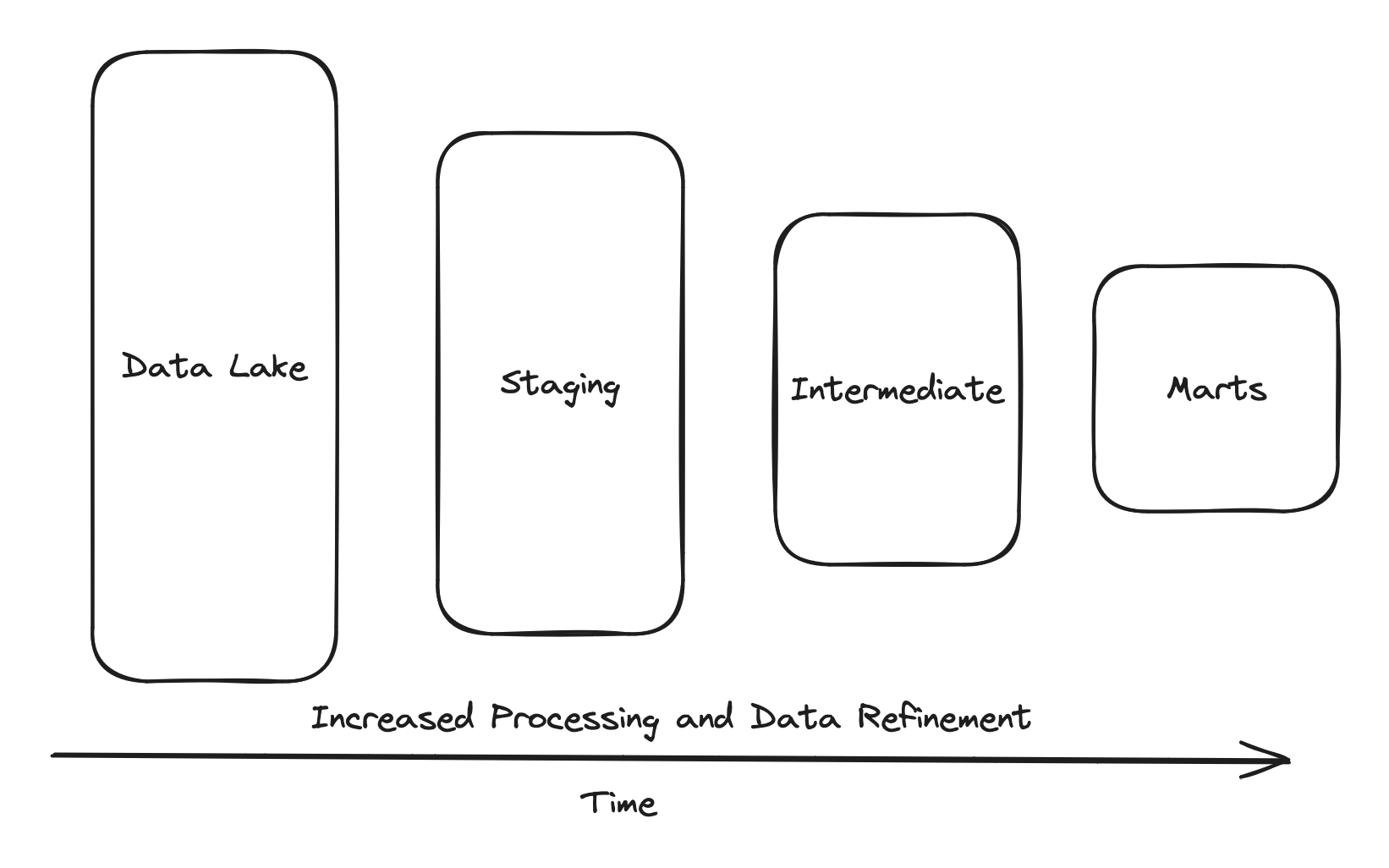
Once in the datalake, data engineering stakeholders have to understand the operational data and refine it into usable metrics. Current best practice suggests metric refinement should be a multi-stage process, each stage imposing more order to the data until insights are finally derrived at the final stage:
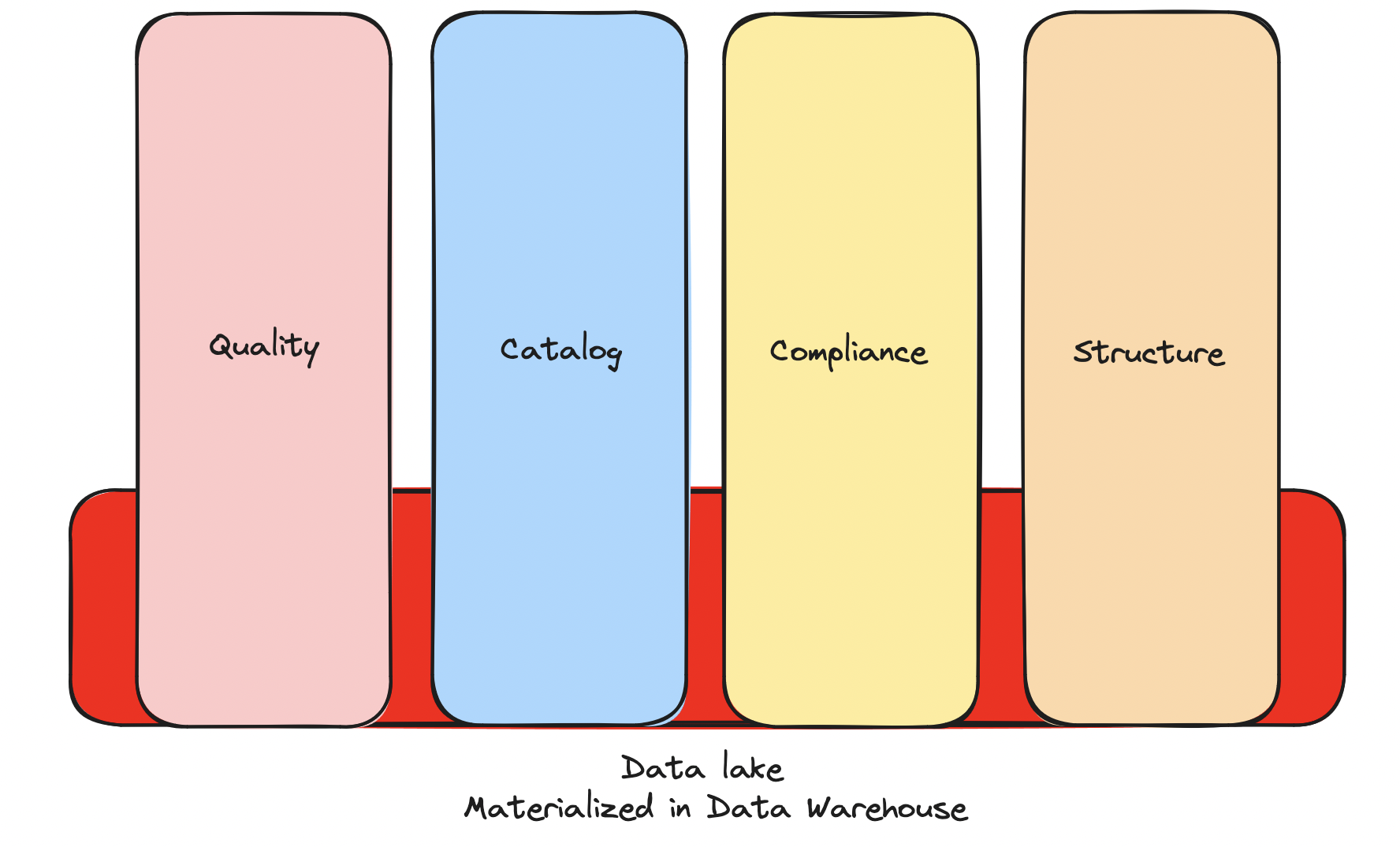
The raw, sometimes unstructured data, living in data lakes necessitate imposing order and structure and other compliance and architectural concerns. These concerns are often layered on by vendors and include: quality offerings, compliance offerings, cataloging offerings and structure offerings.
The raw data requires bolting on operational concerns like quality, structure and compliance through a variety of vendors.
A one-to-one copies a product data is a suboptimal foundation for successful data organizations. The way that linkedin data critics resonate with the industry is testament to this problem and the difficulty facing data organizations. The difficulty of the data organization is a running joke, if only we had schemas, or a product partnership, or structure, if only we could shift left and get product to care about data. This is a shared problem inherent to the ELT approach.
Unfortunately, we can't bolt on success to the data lake primitive, and no vendor will fix the fundamental limitations inherit in the data lake approach.
Accepting a low quality primitive to build huge budget departments off of provides intractable challenges before we even start refining and exposing metrics, and we don't need to accept it. The data lake approach falls decades behind current best software practices around, quality, observability, unit testing, verification, CI / CD, architectural tradeoffs between consistency, availability and costs, and system design best practices.
The ELT successes that we are read about are often backed by gigantic budgets, and are relative to the previous way of doing things. ELT is not the end goal, we can do way better than the "modern" data stack. We can do better for our companies, for our stakeholders, and for ourselves.
What's Wrong With ELT and Data Lakes?
The ELT primitive creates a number of issues fundamentally inherent with the approach of dumping raw operational product data byte for byte into a shared location.
Product/Cloud Data is Fundamentally Misaligned with Analytics
Leaky Domains
ELT and the data lake literally takes other teams and companies operational data and centralizes it for the data organization to make sense out of:
Domain driven design, a popular architectural approach, defines the concept of a bounded context, which are the entities, and relationships in a domain. Domains are owned and managed by product engineering teams and reflected in their datamodels.
Exporting another team's domain requires data to become experts in the domain, the entities, the relationships and the semantic definitions. ELT requires data engineering to become product engineering experts and business experts.
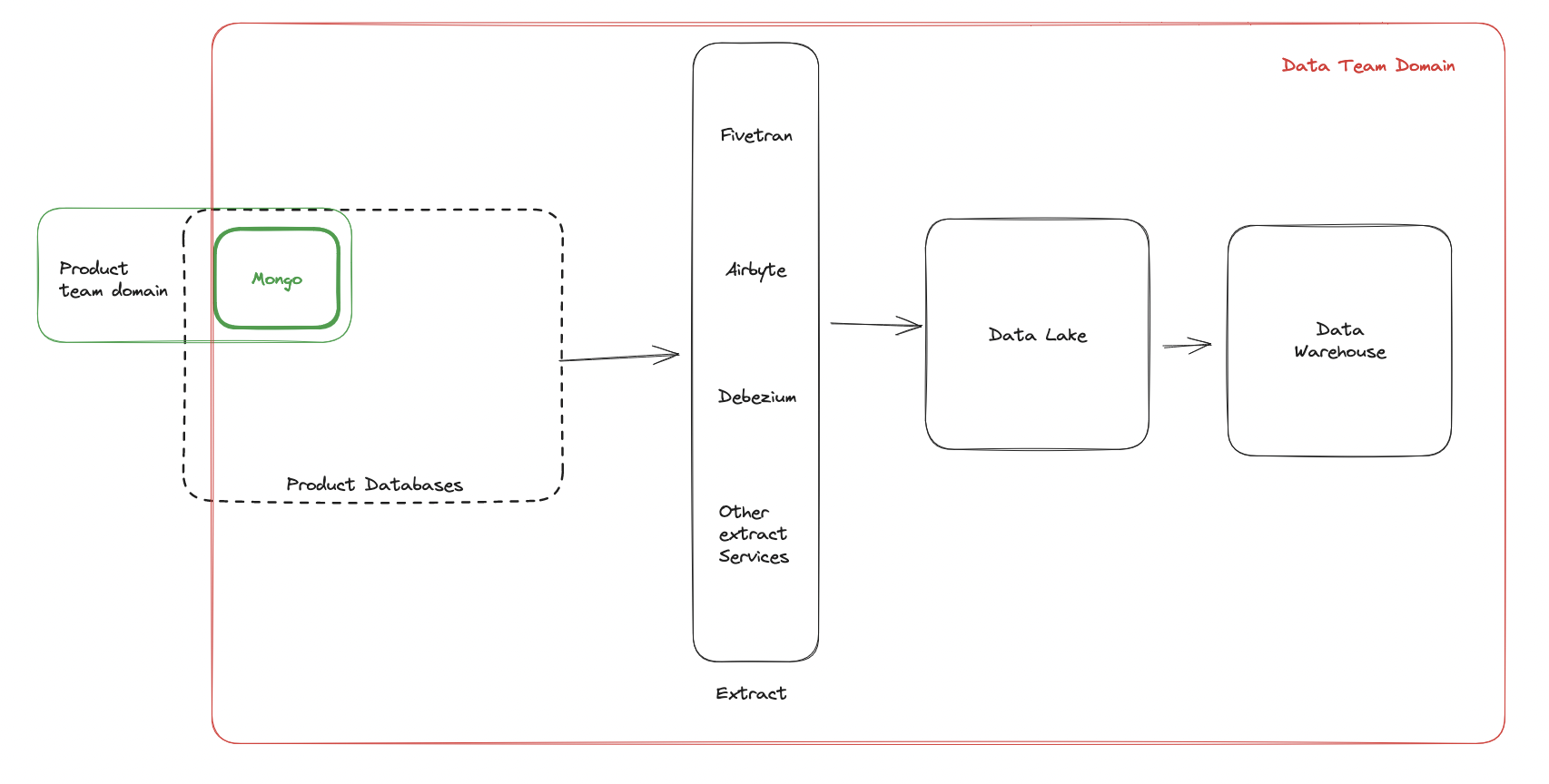
The problem is that the data lake is the dumping ground for all teams, not just a single team. Which exponentially increases the complexity of each domain. Instead of learning a single domain front to back like other domains, data needs to learn N domains front to back.
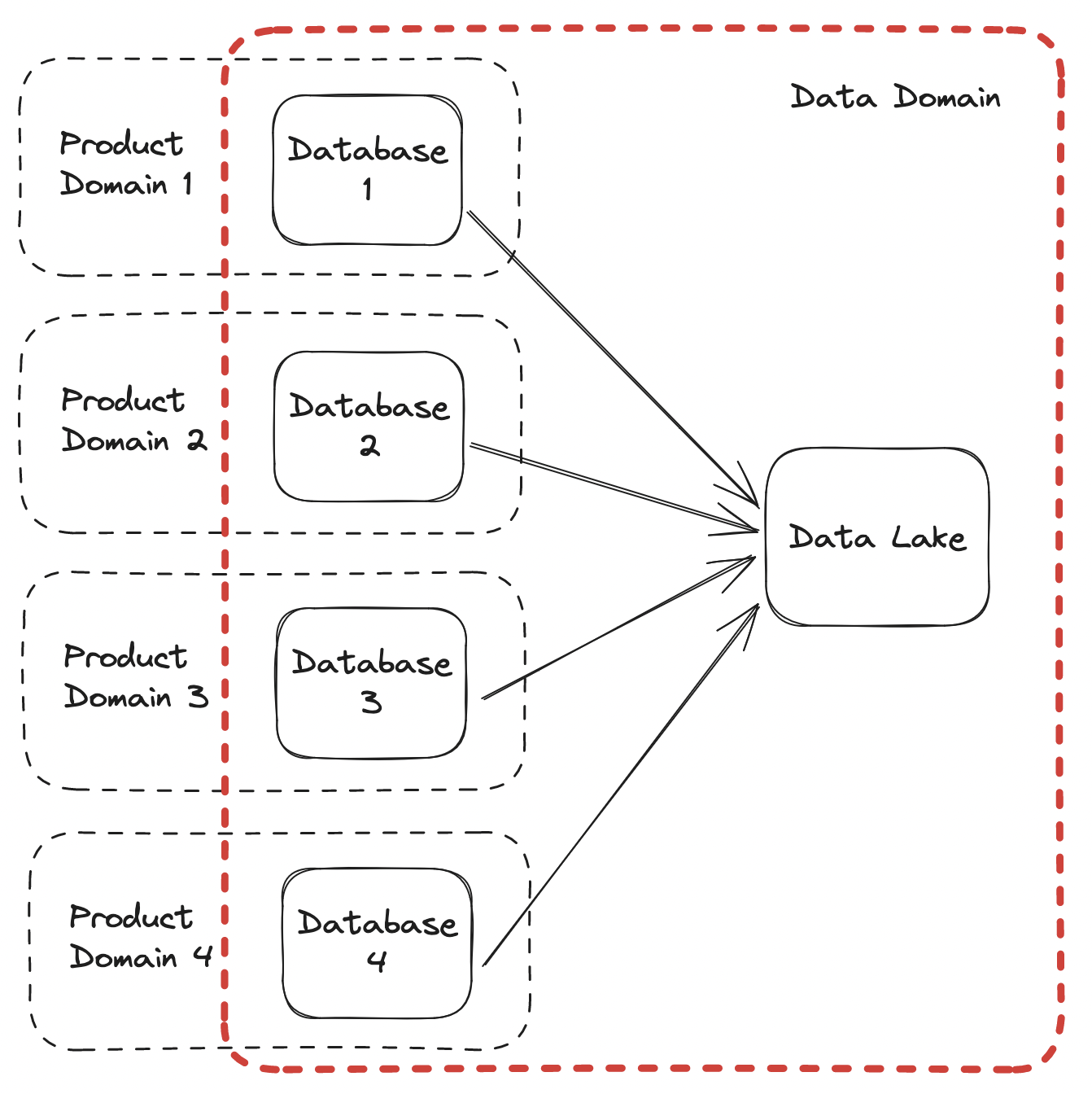
Modeling the domain in the data ware house requires reconstruction or transformation of domain entities, it requires domain expertise. Data needs to understand every teams domain, but often have a fraction of the staff. The entire company funnels requests to data which really has no idea about other teams data.
Before assets are even generated the data team has an overwhelming and unprecedented amount of knowledge to acquire and maintain, more than any other organization in the entire company.
Long Feedback Loops and Expensive Modeling Efforts
The process of producing artifacts from other teams data is plagued with errors. The amount of data and mix of domains require a multi-stage distillation into actionable business insights.
Both the modeling and processing time to get these insights is extremely long. Modeling can easily take weeks while the process of continuously calculating metrics is often batch based, executing on crons with tools like dbt. The modeling and processing is so error prone, due to lack of modern verification tools (like unit tests) that teams need to store a full history of data to give themselves an opportunity to replay history as modeling errors inevitability occur.

This fear of being wrong and losing company trust has caused an industry over correction to store all data indefinitely to support re computation when errors do arise. Data has positioned itself between leadership, product and engineering, requiring assets to change on behalf of any numbers of stakeholders.
Small Refined Datasets
Often times, the results of all the batch based modeling stages are small distilled data marts. Data and metrics are synthesized from the raw unrefined product and cloud data sources in the data lake. Gigabytes or terabytes of data are transferred and stored in the data lake to be aggregated to a small handful of high fidelity business metrics.
This pattern is often reflected in dbt lineage graphs. Large numbers of root nodes are combined through multiple stages of processing to produce a small number of "marts":
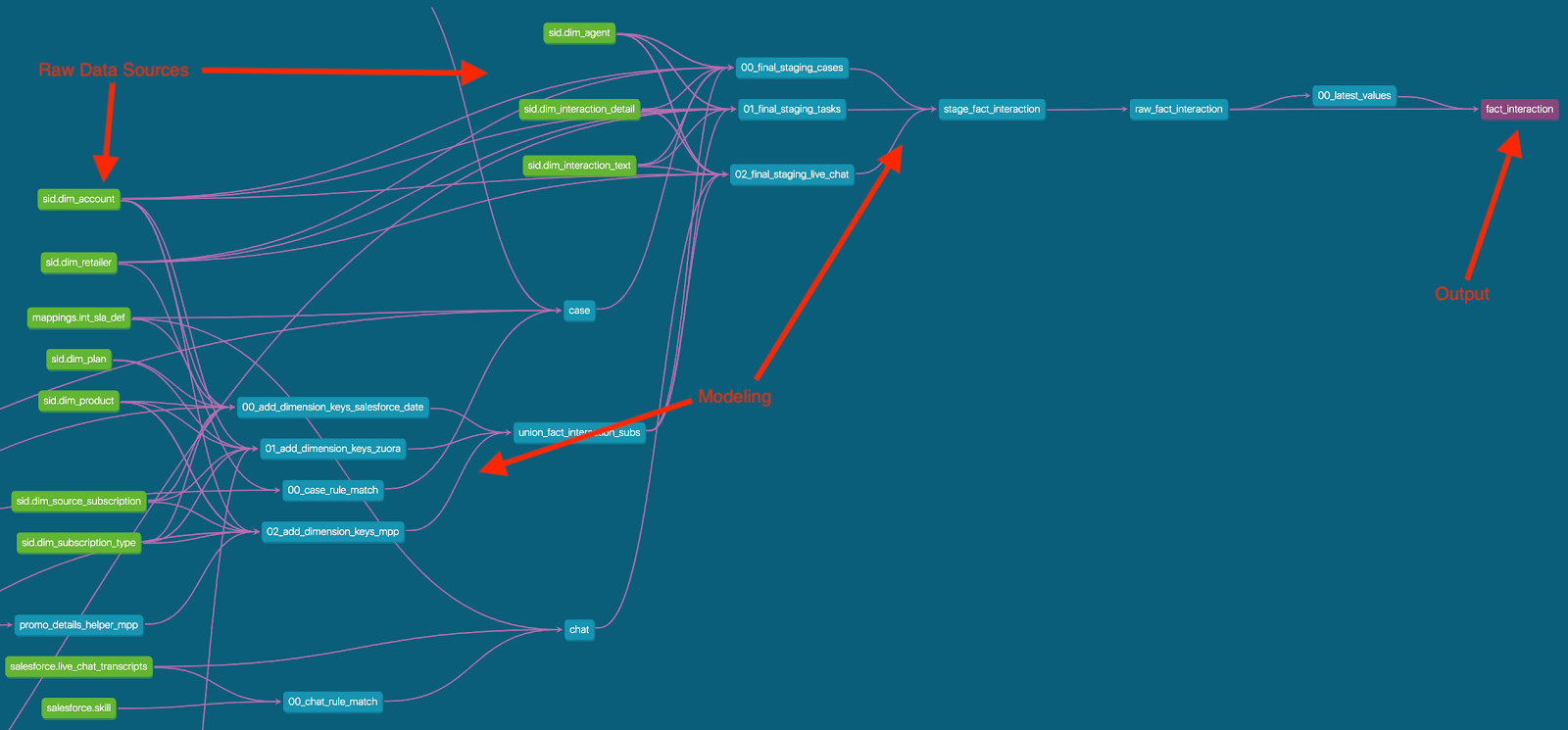
Enterprise data deployments of a certain size begin to take on this pattern. This should be intuitive, it would be impossible for regular stakeholders to understand the raw data requiring that business signals are distilled for regular stakeholders.

Also, just to be clear, this staged problem didn't start with dbt, but dbt has great lineage visualizations that make the pattern very easy to visualize.
Verification Tools are Sparse
The ELT architectural pattern is the verification tool. The fear of missing out on an insight combined with the lack of formal data testing tools has caused an over correction in the industry to store everything under the guise of ELT. While the logic is sound, it causes a strict dependency on data engineering to derive metrics from naturally operational and product data sources sources were not designed for analytics. The sources were designed for OLTP processing and imposing analytic structures on top requires huge amounts of processing, modeling and human understanding on behalf of the data organization. Building analytics on ELT establishes human people based dependencies for business analytics. Trying to transform operational data into metrics is an uphill battle.
Beyond ELT, the verification tools lag decades behind software engineering. The DBT unit testing proposal kicked off in 2020 with design starting in earnest in August of 2023.
When I entered the industry nearly 15 years ago I worked with 1000's of sql integration tests which ran in seconds. Tests exercised every branch of SQL logic and application logic on top of SQL. Transformations, retrievals, persistence, all were covered. Tests ran within the context of a transaction, resetting state just required rollback. I didn't think anything of it because it worked so quickly and easily. An individual test would take milliseconds to run.
ELT is an overcompensation for lack of modern testing tools and poor organizational alignment, favoring storing everything for the fear of making a mistake on behalf of a huge number of completely disparate data stakeholders.
The Availability Numbers Don't Add Up
Shipping huge quantities of data across the world is hard, keeping 100's of individual SQL transformations running is also hard. Not only is it hard but data lags behind software engineering in its approach to modeling error rates and processing uncertainty.
Data has the exception to provide a byte for byte delivery to the data lake for use in downstream data modeling. Software architecture has pretty mature ways to express tradeoffs in designs like these, incorporating tradeoffs between availability or consistency, and high accuracy and cost. These nuances are ignored in the data lake, assuming 1:1 copying.
Unfortunately, the data stack numbers don't add up. No companies make a 100% guarantees, but in data 100% is assumed. Each myriad stakeholder expects 100% accuracy, something software engineering knows is impossible. Even the largest tech companies on earth won't give a 100% guarantee. Amazon offers 9 9's of availability for S3 durability. There are explicitly recognizing that data can be lost.

Fivetran offers 3 9's of extraction availability:
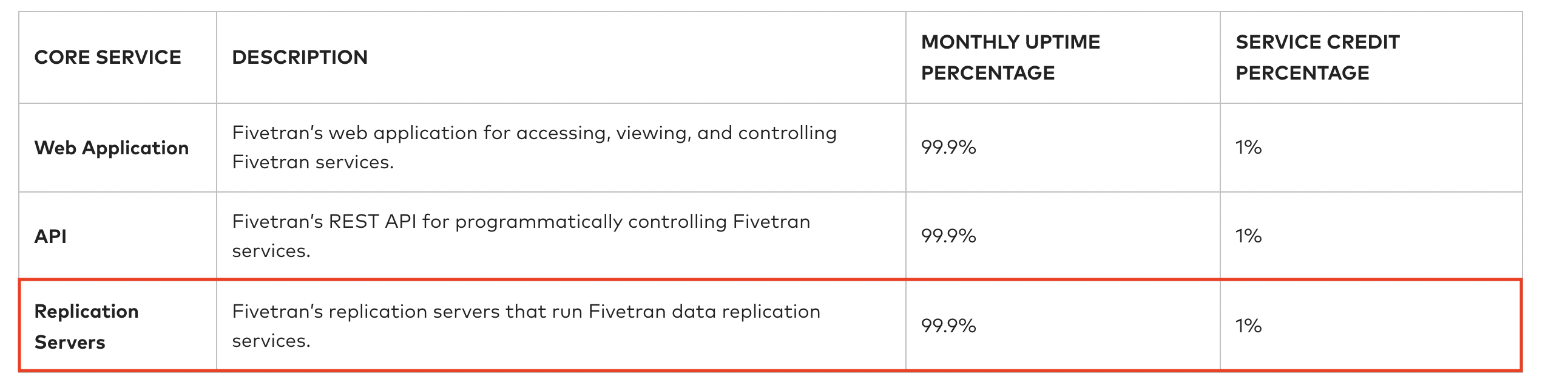
99.9% means a failure is expected every 1000 times. 50 jobs executing hourly means an error is expected per day (50 x 24 hours x 0.001 error rate). While your data sets and the tools may handle these errors gracefully, they still require lots of thought on error recovery and data consistency semantics. It's Hard, and once again data orgs are not often staffed to handle these difficult distributed problems on behalf of every product database type and vendor.
The same goes for refining the raw data on the data lake. If the data team only offers 99% availability of airflow and dbt stages, and has 200 daily jobs that means 2 errors per hour should be expected. Due to the dependency graph nature of SQL model transformations, a failure manifests down the dependency graph, impacting all subsequent processing stages, cascading throughout.
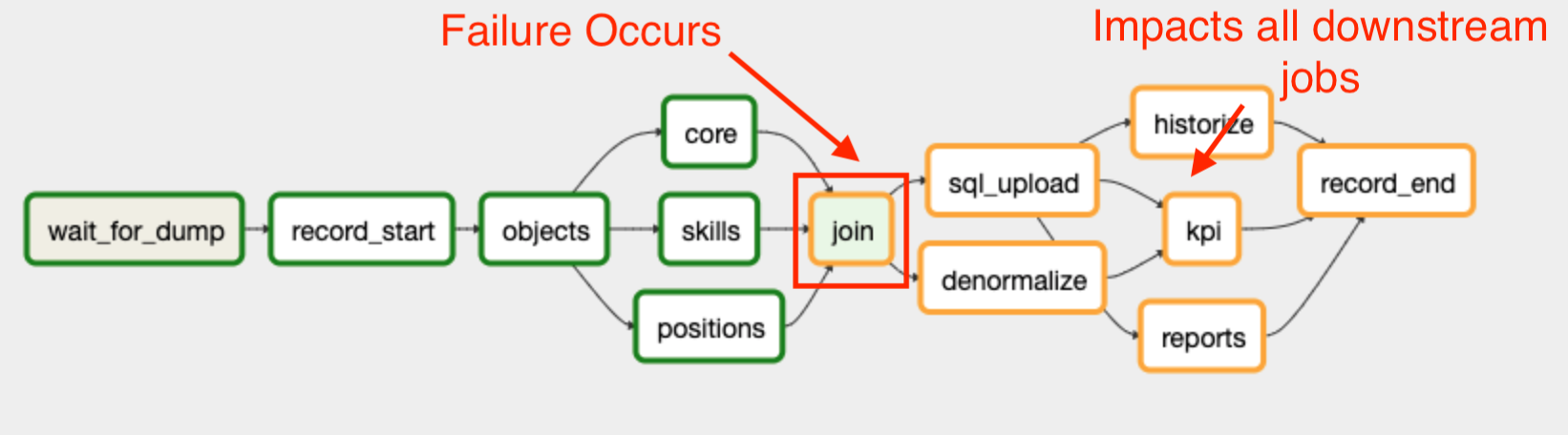
These nuances are rarely modeled in data, but have been best practice in software engineering for years. Data engineering lacks these faciliities to express the tradeoffs between these things and blindly falls back on ELT to replay metrics from the beginning when errors are encountered, at a huge financial cost to the company and morale cost to the team, and breach of trust to the stakeholders.
The Data Lake is a Security Liability
Shipping and extracting data from a huge number of sources to store in a single location. These sources often contain dedicated certifications (such as ISO and SOC), well thought out access controls, and network security controls. Each of the individual sources are often well thought out in their approach to security. Often times the data org isn't staffed as well as the product organizations and many of these first class concerns are second thoughts.
Once the data org realizes there is a problem, an attempt to bolt on these concerns but still a 24x7 ongoing and perpetual concern for perpetuity due to the fundamental approach of egressing and storing everything in the data lake..
There's no argument here. For some reason data takes responsibility of toxic assets. I think of the plot line for HBO's Succession. An aspiring executive gets looped in on a cover up. Part of his protection is shielding the executives from the liability of coverups. Storing every team's and cloud's private data is a rough ask. Once again the orgs are usually not staffed for this, but responsibility falls onto the data team because of ELT approach.
Conclusion
I hope that this post clearly outlined some of the major foundational flaws inherent to the ELT approach. Part 2 of 3 will look to successful software based data systems for inspirations on how we can re imagine the role of data engineering and the data organization. Part 3 of 3 will offer concrete solutions and strategies (this isn't all complaining) on how we can address this as an industry by adopting software engineering best practices and applying them to our data resources!