- Published on
Calculating Monthly Active Users (MAU)
- Authors

- Name
- Danny Mican
Monthly active user is a common product usage metric used to represent the popularity and engagement of a product. The definition is pretty simple and involves a single numeric count of the number of users that perfomed an activity in a given month.
- Monthly - Usually a calendar month. The count resets on the first day of each month.
- Active - A user activity, often associated with a paid resource, such as a critical operation, or access to a report or dashboard.
- User - An indivudal actor that performs the activity.
A single MAU number is helpful to see overlall product growth. MAU is often split by customer to help understand customer-specific engagement and usage.
A user is represented by a user identifier. Identifiers may be machine generated but may also be natural identifiers like an email.
Challenges
The challenge with MAU calculations is each month needs to keep track of the full set of users that took action in the month. If a product has a customer with 300MM users, that means MAU needs to keep track of potentially 300MMM user ids.
Unfortunately MAU is a set which means it can't be derrived from daily counts of user logins (DAU).
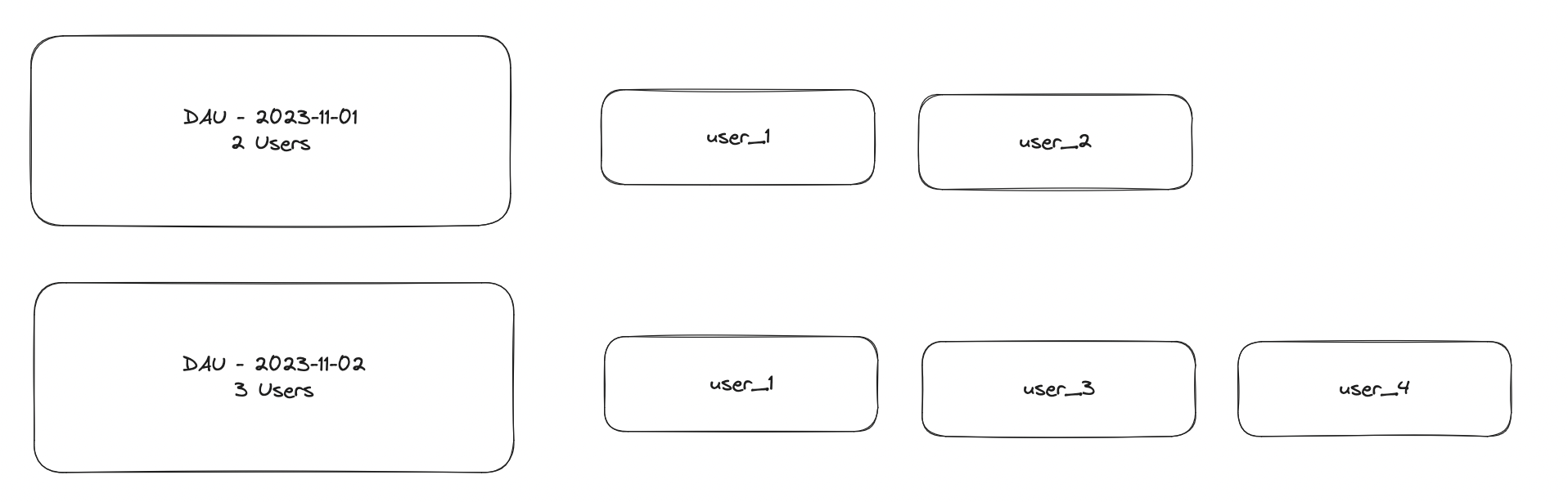
Summing these 2 days to produce a running monthly count would result in a count of 5 users (user_1, user_2, user_3, user_4, user_1), which is incorrect because it double counts user_1 on 2023-11-01 and 2023-11-02.
The correct way to calculate this is to treat each collection as a set of user ids and not a list of user ids. The set of user ids can then be UNIONed to produce the correct count of 4 active users:
DAY 1 {user_1, user_2}
U
DAY 2 {user_1, user_3, user_4}
= 4 Active Users {user_1, user_2, user_3, user_4}
Basically, calculating MAU is not as straightforward as counting user activities. Active users should be thought of as a set and not a count or a list.
Storing Discreet User Activities
MAU can be calculated from a group of user activities occuring in a month. This approach is commonly used in event based systems to calculate MAU. These systems emit a stream of "usage" events to queues, such as kafka. The events are persisted in a data lake or data warehouse and are exposed for query.
Imagine the activity that is being tracked is a successful HTTP request to a paid endpoint, in this example /access. The software would create an emit an event for each user interaction. Each event would track the user activity and the user taking that activity:
# user_activities
{
endpoint: "/access",
status_code: 200,
time: "2023-11-10Z00:00:00.112",
user_id: "1234234-1243123-adsfasd-123",
customer_id: "amazon"
}
The MAU calculation would query each of the discreet events and aggregate by customer and distinct user_id count:
SELECT
COUNT(DISTINCT user_id) as mau_count,
customer_id
FROM
user_activities
WHERE
endpoint = '/access'
AND status_code = 200
AND time::date >= '2023-11-01',
AND time::date <= '2023-11-30'
GROUP BY
customer_id;
The complexity of this approach is the storage of each user interaction. High traffic services can generate thousands or 10's of thousands of events per second. Each event needs to be persisted and scanned to query. This can result in huge amounts of data stored to derive a couple of kilobytes of MAU monthly data! Additional, many moving parts and high availability services are required to publish, store and query discreet activity events.
The benefits of this approach include:
- Lends well to the data lake pattern, where streams of data land in the datalake.
- It's easy to replay history since each individual user interaction is captured.
Maintaining a User Activity Set
The next strategy involves maintaining a set of user activities for the given month.
This could be implemented on redis using the SET datatype:
SET MAU:2023-11:<CUSTOMER_ID>
Whenever a user activity occurs the product service will add the activity to the MAU set for the current month and customer:
SET MAU:2023-11:amazon "user_1"
This approach has a number of benefits including:
- Constant time user_id MAU tracking
- Constant time MAU monthly count retrieval
Careful attention needs to be paid to the potential number of users for any given customer. Suppose that a UUID4 is used for the user identifier. Each user id will be 16 bytes per identifier.
A customer with 350MM users will require (350MM * 16 bytes) or 5.2GiB / Month. Careful attention needs to be paid to the total storage required across all your customers and their potential maximum users.
Approximate User Activites
Approximating MAU counts also store a set of user ids for a given month, but instead of a traditional SET this approaches leverages a probabilistic set such as HyperLogLog. HyperLogLog can track billions of user ids in a fixed amount of space (12KiB), in redis.
The semantics of using hyperloglog mirror the redis set:
PFADD MAU:2023-11:amazon "user_1"
THe major drawback is that the cont is estimated and is not guaranteed to be accurate. The Redis implementation provides an error bounds of 0.81%. This means a customer with 1MM users can expecut up to a (1MM * 0.0081) 8,100 over or under count.
The probabilistic set provides extreme space savings over the standard set. Each customers MAU is stored in a max of 12KB no matter how many user ids are observed in a given month.
Counting User Login Times
The final approach leverages metadata stored about the user login time. Assuming that the last login time is stored in the product model somewhere, the counts can be queried to calculate MAU.
Assume a data model like the following:
user_id STRING
customer_id STRING
last_login_time DATETIME
The data model can be directly queried to calculate MAU:
SELECT
COUNT(DISTINCT user_id) as mau_count,
customer_id
FROM
users
WHERE
last_login_time::date >= '2023-11-01'
AND last_login_time::date <= '2023-11-30'
GROUP BY
customer_id;
The benifit of this is that minimal additional persistence is required for the owning team. Each months count needs to be persisted somewhere, but the bulk of the state of MAU for the given month is stored on the actual product database.
Comparison
| Replay History | Accuracy | Storage Cost | Query Cost | Complexity | |
|---|---|---|---|---|---|
| Storing Discreet User Activities | YES | YES | HIGH | MEDIUM | HIGH - Many high availability services required. |
| Storing User Activity Set | NO | YES | MEDIUM | LOW | MEDIUM - Storing set in redis is trivial. But MAU still needs to be exported. |
| Approximate User Activity Set | NO | NO | LOW | LOW | MEDIUM |
| Counting User Login Times | NO | YES | LOW | LOW | MEDIUM |