- Published on
StaffPlus - An Algorithm For Getting Stuff Done
- Authors

- Name
- Danny Mican
True effectiveness at the staff level is not about producing good ideas, but instead about executing outcomes. Success is about execution. Execution at the StaffPlus level requires partnerships across the org. Initiatives are often beyond the scope of a single team, or require significant resource buy-in from management. Larger initiatives may require partnership with other teams and units across the entire org. I find myself using the same approach for every initiative that Im trying to make a reality:
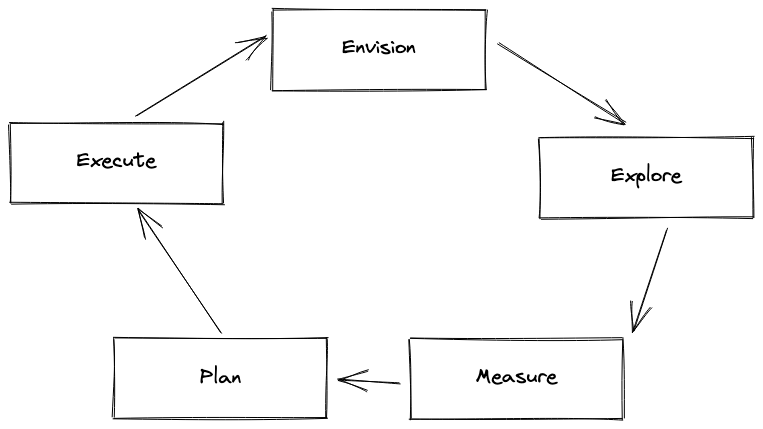
- Envision
- Explore
- Measure
- Plan
- Execute
- Repeat
I have found that getting things done in a StaffPlus role requires a mix of roles and responsibilities:
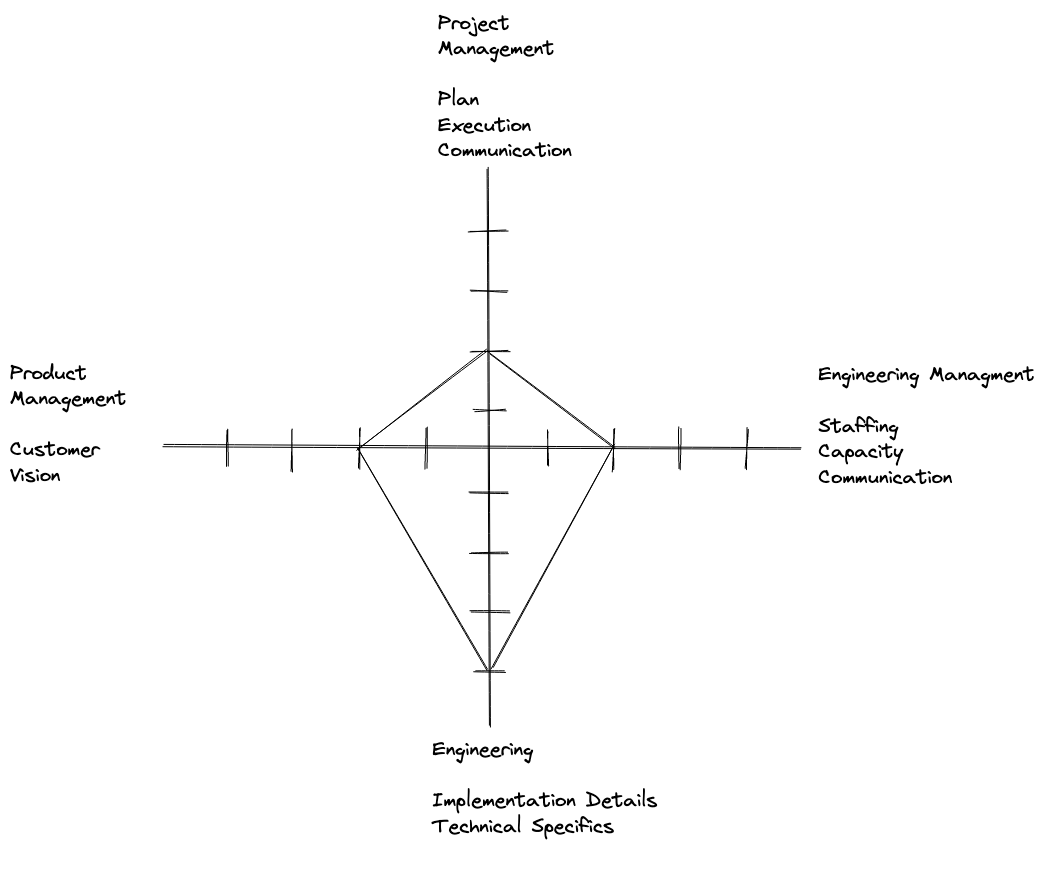
The radar chart above shows how the bulk of the skill is weighed towards technical details, but each of the skillsets are required to get stuff done.
Accomplishing tasks require partnerships, but executing at a Staffplus level effectively requires a mix of different techniques pulled from different roles. Execution requires a mix of:
- Engineering: Deep technical understanding of implementation details. Either first hand knowledge or the ability to acquire the knowledge. This will be essential for the Planing step.
- Product Management: Understanding the customer, having a vision, measurement, and customer-facing communication.
- Project Management: The ability to create and execute a project plan. The ability to keep up to date on project status, and communicate that to relevant stakeholders.
- Engineering Management: Understanding of staffing, capacity, concurrent commitments and the ability to communicate to skip level and peers.
Algorithm
An algorithm is a recipe for accomplishing a task. This is a way to approach a problem and decompose it into a set of concrete steps.
The problem in this case is to make an idea a reality "get stuff done". Success is turning that idea into reality (or quitting fast before investing too much time). Failure is the idea remaining an idea.
I create a document for each initiative where I write down the research, findings and results from each step. A written plan provides a shareable artifact and solves for asynchronous communication of the idea and plan.
Envision
Have a vision. What do you want to accomplish? What will the world look like when you do? This step ideates, it incorporates perspectives and leverages your own experience and creativity. Envisioning requires talking to stakeholders, partners and peers and distills a new reality. Some initiatives will be "team-local" where you are completely empowered to change within your own team, but other larger initiatives will require this partnering across the organization.
This stage should produce a document describing the future reality.
Skills: Engineering, Product Management
Explore
Explore focuses on understanding and documenting the current state of reality. Exploration should focus on data to back up the idea. Explore should either:
- Provide enough data to support the vision
- Provide enough data to invalidate the vision
Invalidating an idea is just as important as executing an idea. Not every idea will work, it is much cheaper to invalidate an idea or vision shortly into the cycle before significant time and money is invested.
Exploration also requires getting clarity on the specifics of the current implementation. If your vision is to simplify a company process, you must understand the current process in order to modify it and make it simpler. If the vision is to reduce tech debt by simplifying core business functions, or restructuring hard to test software, you must understand the implementation of the current software to safely modify it.
Exploration focuses on understanding the reality as it is today. Understanding the current state is necessary so you know what exactly needs to change to move the current reality towards your vision.
Skills: Engineering, Product Management, Project Management, Engineering Management
Measure
Measurement provides a way to surface the impact of your initiative. It leverages the "Explore" result, but it is ongoing, unlike explore which is a point in time investigation. If the vision is to make deployments safer, a measurement may focus on the current rate of deployment errors, and ensure that the work executed for the vision reduces this number. Measurement is ongoing. Ideally measurement will be automated but if not, metrics should be pulled at an interval sufficiently small enough to track progress (weekly or monthly).
Skills: Engineering, Product Management, Engineering Management
Plan
Planning takes the vision, backed by data on its viability and creates a concrete path for delivery. A plan is an executable sequence of steps, required to turn the current state of reality. The steps outlined in the plan may be logical, or go into the implementation details, depending on your target audience. The plan removes all ambiguity and makes each step bounded and known.
Removing ambiguity may involve getting your hands dirty, running small experiments, speaking to subject matter experts, or learning new code.
A plan defines the timeline, and capacity necessary to achieve the timeline. The plan represents a concrete ask on staffing, and provides decisions makers information on:
- How many people are necessary?
- For how long are they necessary?
- What will they work on and in what order?
- What specifically do they need to do to reach the goal?
Skills: Engineering, Project Management, Engineering Management
Execute
Execution completes each step in the plan. This is "doing-the-work". The hard part is already done in the previous steps! The work is unambiguous thanks to your plan. Thanks to the upfront planning execution is the mechanical changes necessary to modify the system to accomplish the vision. This is adding code, modifying the system, and changing things.
If the previous steps were done correctly execution should be rote and mechanical. Discovering new information about the task is a smell that the previous tasks were not fully completed. The market may change, customer requests may change, but implementation details should not be discovered during this stage. Implementation details are fully controllable and should be known before execution begins.
Skills: Engineering, Project Management, Engineering Management
Repeat
The algorithm completed! The state of reality is one step closer to the vision, execution succeeded, there are metrics to prove the impact! It's time to celebrate and start envisioning the future :).
Advice
Keep the loop tight. Demonstrating value and attacking the metrics in incremental pieces provide the company with a "win". It's easy to fall into a trap of scoping work too big, and not fully delivering this work. A company will only tolerate so many mis executions. You'll either lose your influence and reputation or even worse flat out get laid off.
Know the implementation details off the top of your head. Someone needs to understand the technical specifics of what will change. As a StaffPlus leader this person should be you. Even if you don't do the initial research, you should be able to point to the technical specifics that execute the plan, what needs to change where and why it needs to change.
Keep track of every stage of the project, and be able to comunicate it as well as the project manager. This is your vision becoming a reality. Whether you are the one doing the work or not, you are the advocate for it, your reputation and plan is making this a reality, you need to understand the project status, how the metrics are impacted and risks to the project.
Example
This section applies the algorithm to the example of "Reducing Test Flakiness" to illustrate how it works.
Envision
As a StaffPlus you notice that engineers are spending lots of time waiting for builds to run. People are complaining about how long and flaky tests are and how little value they provide. Engineers are wasting hours a week just ... waiting for tests to run.
You envision a better way. Tests are important but the current test time is causing more problems than it prevents.
You begin by creating a document to begin documenting your thoughts and approaches. You outline the goal of "Reducing test suite execution time by removing flaky tests".
Explore
Starting with your hypothesis you begin researching data on the current test execution times. You find that the average test suite execution time is ~45 minutes, and on average each commit has to retry 1 time. You meet with engineers familiar with the test suite and interview them, to ask them how frequently they find that the test failures indicate a true positive bug. The overwhelming response is that they rarely, if ever, indicate a real bug.
You dive into the implementation of the test suite to understand which tests are flaky, producing a short list of 10 tests. You identify 3 tests failing due to timing errors, but the other 7 use a deprecated approach leveraging docker compose and selenium.
You also profile test execution time to understand how much time each test is taking to execute.
This analysis confirms 2 main classes of "bad" tests:
- Tests that are flaky (i.e. indeterminate) and rarely find bugs
- Tests that take a disproportionately long amount of time to execute.
This stage documents the state of the test suite, using both empirical data, based on execution time and test suite composition and qualitative data based on interviews. You've confirmed that your vision is achievable, but also learned that flaky tests are not the only culprit for the long test suite execution!
Measure
You'll use the same methodology to regularly pull test suite execution time. Your build tool (i.e. GitHub actions) provides test suite duration time, and your test harness logs the start times and end times of test suite runs, and individual test runs. You decide to pull these metrics every other week and visualize them in a google sheet. While suboptimal this is perfectly sufficient to show the effectiveness of your initiative.
Plan
Now it's time to create the concrete steps required to achieve your vision of reducing test suite execution time. You decide to handle the tests in a number of ways:
- Partition the test suite into "unit" (fast) tests and (integration) "slow" tests, executing fast tests before slow tests in the build stage.
- Refactor the 3 times with flaky timing to using polling or an asynchronous communication mechanism
- Refactor 6 of the 7 tests using the old docker-compose and selenium approach, to leverage
testcontainers - Remove the 7th test with no equivalent
- Half of the "long" tests can reduce their scope and be rewritten to remove IO
- The other half are untouched and remain classified as "integration" (slow) tests
You sequence the work so the first step is the test suite partitioning into (unit & integration) and labelling of each test. Each subsequent task can be performed concurrently to all other remaining tasks. You scope the work to clearly explain the implementation of each task, linking to code required to achieve the desired outcome. You tee up the work for anyone to pick it up and begin executing.
Execute
Work is scheduled! It takes 3 sprints of limited capacity. After each sprint you pull the metrics to show the impact of the work on the execution time of the test suite. Each body of work reduces the average test suite duration and begins to reduce the number of retries!
Repeat
You crushed it, you told the story, you executed smoothly, you tee'd up work for anyone on your team to take, and you told the story of the impact of that work! Time to look to what's next :)