- Published on
Introduction to How External Partitions Work in Systems Like Redshift Spectrum
- Authors

- Name
- Danny Mican
When I started using Spectrum and Athena I was confused by partitions. I found few resources and examples on how partitions actually worked. This article explains how partitions work in spectrum. It explains how queries against partitions work and clarifies what partition keys are and how they relate to underlying data.
Generic File Backed Tables
Generic file backed databases store data in flat files. These files are commonly serialized as csv, json, parquet, ORC. These differ from traditional databases because they allow the application to generated the data, and the database to read it. Traditional databases have proprietary storage formats, which doesn't allow interchange of data between different databases. Generic file backed tables the storage is decoupled from the compute layer. This means multiplied different databases can be pointed at the files, including: snowflake, redshift spectrum, Athena and presto. Generic file backed largely enable data-lakes and power extract load transform (ELT).
What Are Partitions?
The concept of partitioning isn't specific to File backed tables. Partitioning just describes splitting up data. Any directory on a filesystem partitions data. Partitions allow drilling into data. Partitions are a way to modify run complexities of database lookup times. To illustrate consider an encyclopedia. Assume that the data for each entry in an encyclopedia is located in a file.
# cat.txt
Name: cat
Description: furry creature
Etc..
One option would be to store each file in a flat directory:
encyclopedia/
...
cat.txt
...
dog.txt
...
mailbox.txt
...
zebra.txt
Finding an entry using the flat directory results in a linear O(n) time. If a user looks up the entry for "zebra" every single file would have to be visited.
Partitioning in file backed storage buckets data using a file path. One way to partition the encyclopedia data is to partition it by first letter:
encyclopedia/
...
c/
cat.txt
d/
dog.txt
...
z/
zebra.txt
Now if a user searches for "zebra" only the "z's" would have to be consulted. The program is able to ignore every other letter! Redshift spectrum and the "Presto" class of databases often operate on terabytes, petabytes, or even exabytes of data!
Common partitioning strategies are:
- Date - YYYYmmdd
- Hour
- Event type
- Anything else that is commonly used in a "WHERE" clause or any other predicate to limit the result set.
Partitions can also be combined to form a hierarchy:
day=YYYYmmdd/hour=HH
This partition enables drilling into an individual day:
WHERE
day='20201005'
or an individual hour:
WHERE
day='20201005'
AND hour='23'
Defining Partitions
Flat file backed tables and partitions have 3 different components:
- The table definition including the base path of data
- Partition keys
- Partition entries
Amazon provides documentation describing each of these components, which we'll use here to illustrate.

This table definition tells redshift that all data for this table is located in:
s3://awssampledbuswest2/tickit/spectrum/sales_partition/
The partitioned by tells redshift that directory has multiple subdirectories (the partitions):
s3://awssampledbuswest2/tickit/spectrum/sales_partition/
saledate=2008-01/
saledate=2008-02/
...
The partition only refers to the directory structure and not the underlying data. This really confused me at first. The data contained inside of this s3 repo does not have an indexed saledate property. Presto-like databases know that when a partition key is used in a predicate, they need to search the available partitions and not the underlying data.
An additional step is required which is actually adding the partitions. Suppose we apply the create table listed in the image above, and issued a query:
SELECT
salesid
FROM
spectrum.sales_part
WHERE
saledate='2008-01'
Redshift would return 0 results for this even though the underlying data exists. This happens because redshift consults a partitions collection (viewable as SVV_EXTERNAL_PARTITIONS) for all partitions associated with a table. Since no entries have been added for saledate='2008-01' it does not know of any data associated with this query.
Presto like databases require that you add entries for each partition that is searchable. ADD PARTITION maps partition keys in a query to underlying file system paths:
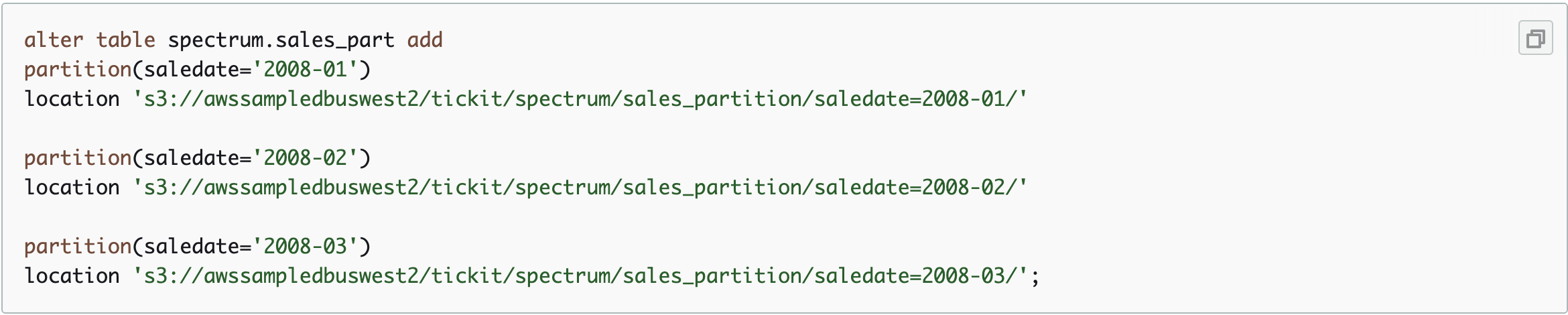
Now if you rerun the query, redshift will see that saledate is a partition key, it will then look in its partition collection and see that a partition exists. It now knows which filesystem path to query for he correspond saledate='2008-01' data.
Remember This
- Partitions are defined as keys in the table definition but the keys don't map to underlying data. The keys ONLY reference the file paths.
- Partitions must be added for the database engine to query the underlying data. The table definition isn't enough. This means you might have to run a daily job to add your partitions, or check if partitions exist before you execute each query.
- Partition hierarchy can be important. Redshift Spectrum will query sub partitions in parallel. This means if you have a partition like:
s3://data/$day/$hour/
If you execute a query for a given day:
WHERE
$day='20201105'
Redshift will query each hour in parallel!
If there's one thing to remember it's that partitions sit on op of the the underlying data and when partition keys in WHERE clauses do not actually query the underlying data.
Happy Partitioning!